一、现象
该机器的RegionServer的CPU几乎吃满,造成负载过高。
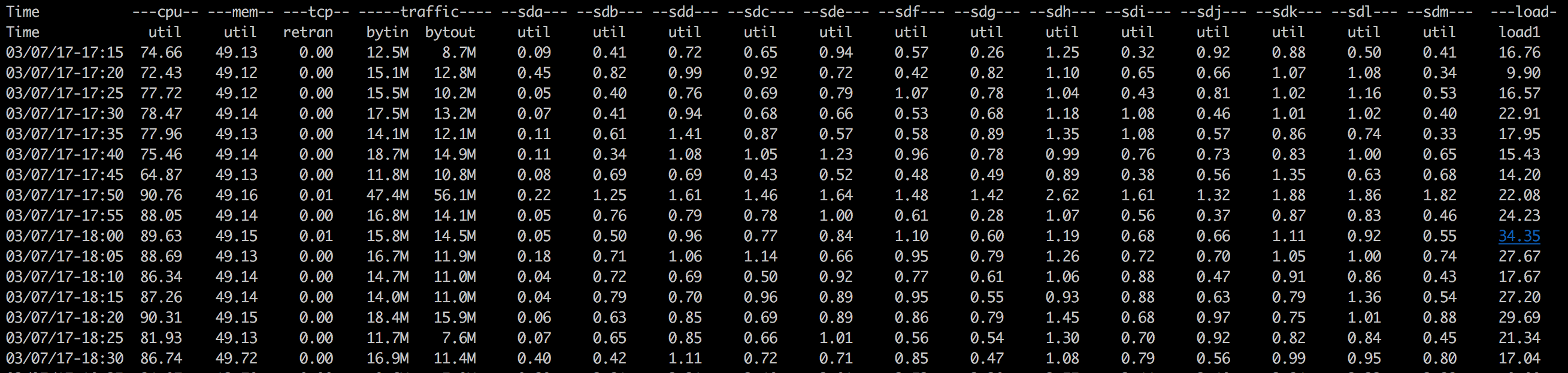
二、定位
通过top -H -p + jstack 组合,找到消耗CPU的TOP 20线程,发现大量是Metrics线程,如下:
|
|
可以使用如下脚本,获取top N的线程:
|
|
使用方法:
|
|
输出:
|
|
三、临时解决
重启后恢复。
四、真实原因
抓取到线程CPU消耗在metrics.updatePut方法,内部采有JDK的ReentrantReadWriteLock实现,出现问题概率不高,可能是表象。貌似是hbase的一个bug,已经进行了修复。https://issues.apache.org/jira/browse/HBASE-15222