故障时间:2017-06-04 09:15
一、现象
RegionServer自行挂掉:zk + shutdown hook
|
|
从之前的日志发现了大量:
|
|
从表面现象看,这个和DirectMemory发生OOM有关
二、初步检查
1. 配置不均:
HBase-zw中只有如下机器配置了bucketcache.size,但是配置略有不同。
| 序号 | 机器 | MaxDirectMemorySize | bucketcache.size |
|---|---|---|---|
| 1 | 10.10.102.68 | 13G | 12288(12G) |
| 2 | 10.10.102.69 | 7G | 6144(6G) |
| 3 | 10.10.102.70 | 7G | 6144(6G) |
| 4 | 10.10.102.71 | 7G | 6144(6G) |
| 5 | 10.10.102.72 | 7G | 6144(6G) |
| 6 | 10.10.102.73 | 7G | 6144(6G) |
| 7 | 10.10.102.226 | 7G | 6144(6G) |
| 8 | 10.10.102.227 | 7G | 6144(6G) |
| 9 | 10.10.65.86 | 7G | 6144(6G) |
| 10 | 其他机器 | 没有显式指定 | 无 |
|
|
2. 内存统计
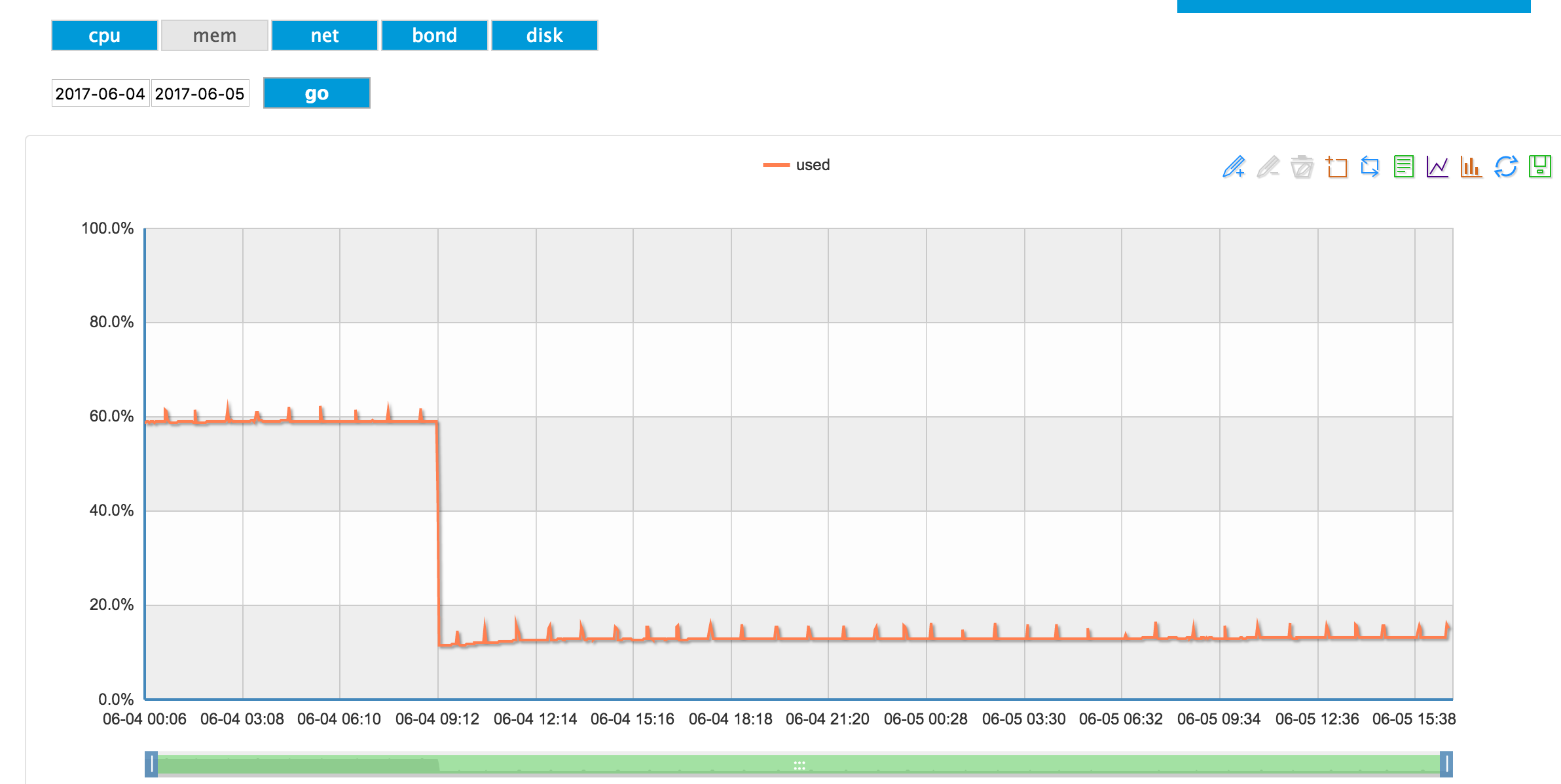
在RegionServer挂掉后,内存下降(正常情况),之前内存在60%左右,应该是正常
(1)mm统计:
(2) tsar统计
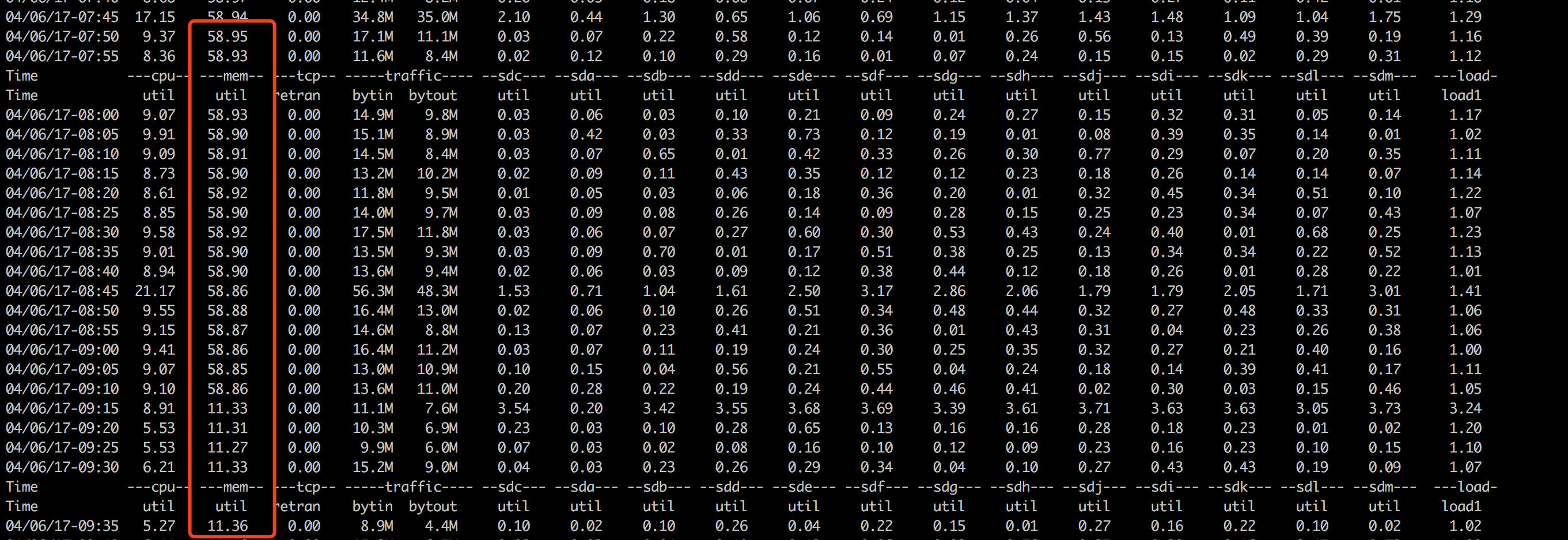
3. 读写量
从读写请求量看基本属于正常情况。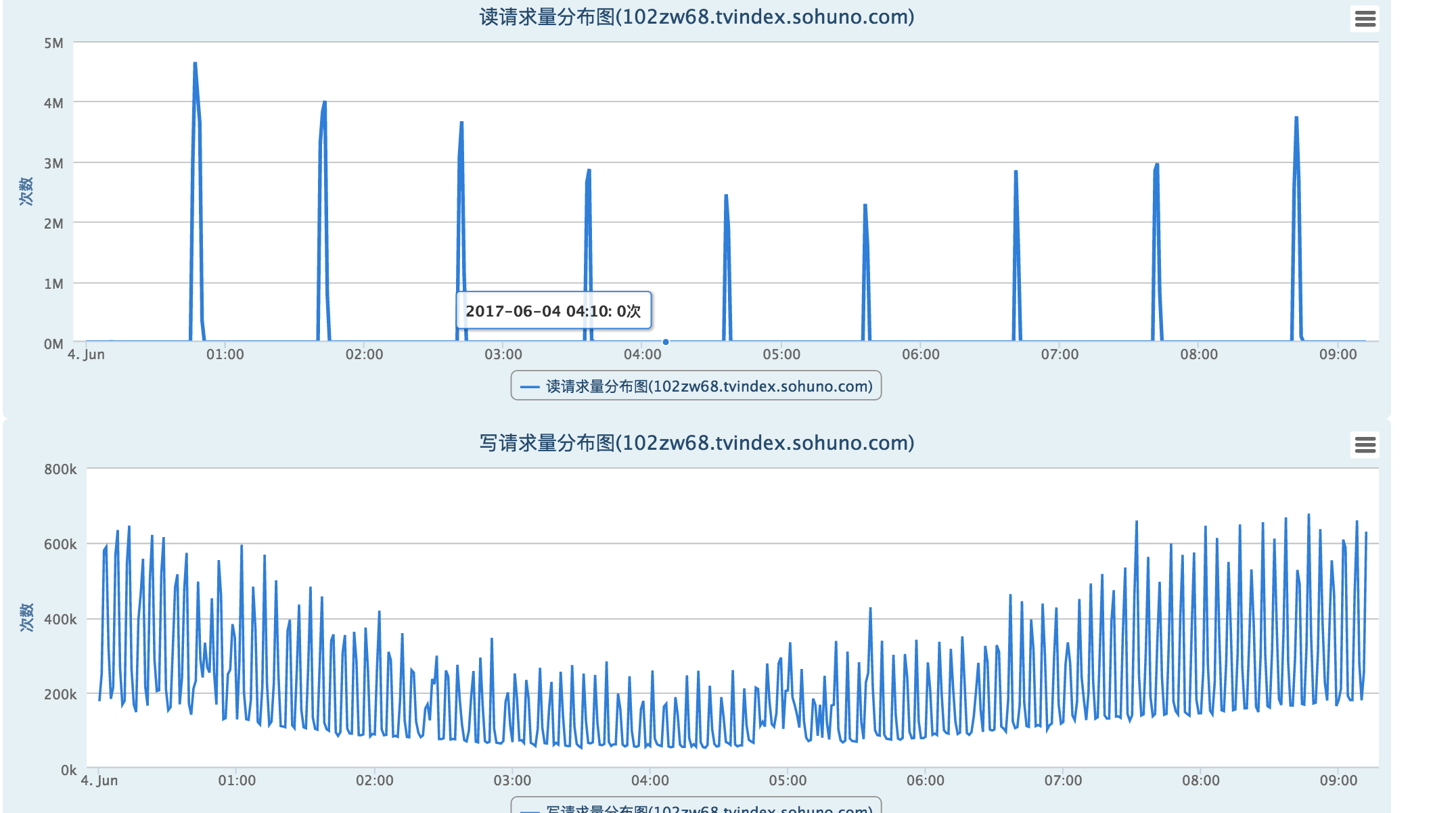
4.GC
(1) 从图表看比较正常。
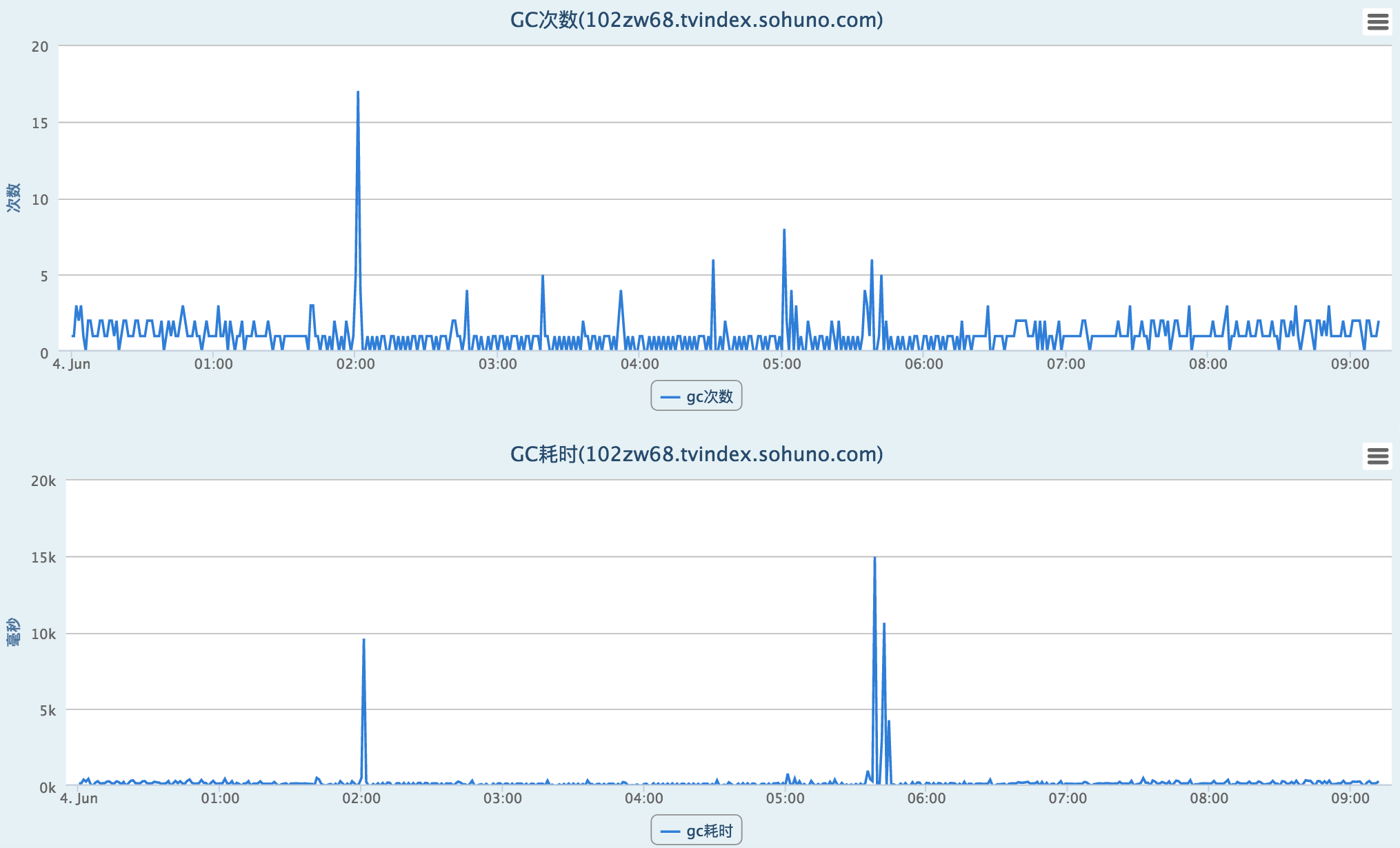
(2) gc日志:
09点12开始发生了很多次fullgc:
|
|
从上面的内存变化可以看到,这种fullgc显然是不正常的,从历史的堆统计看以看到:
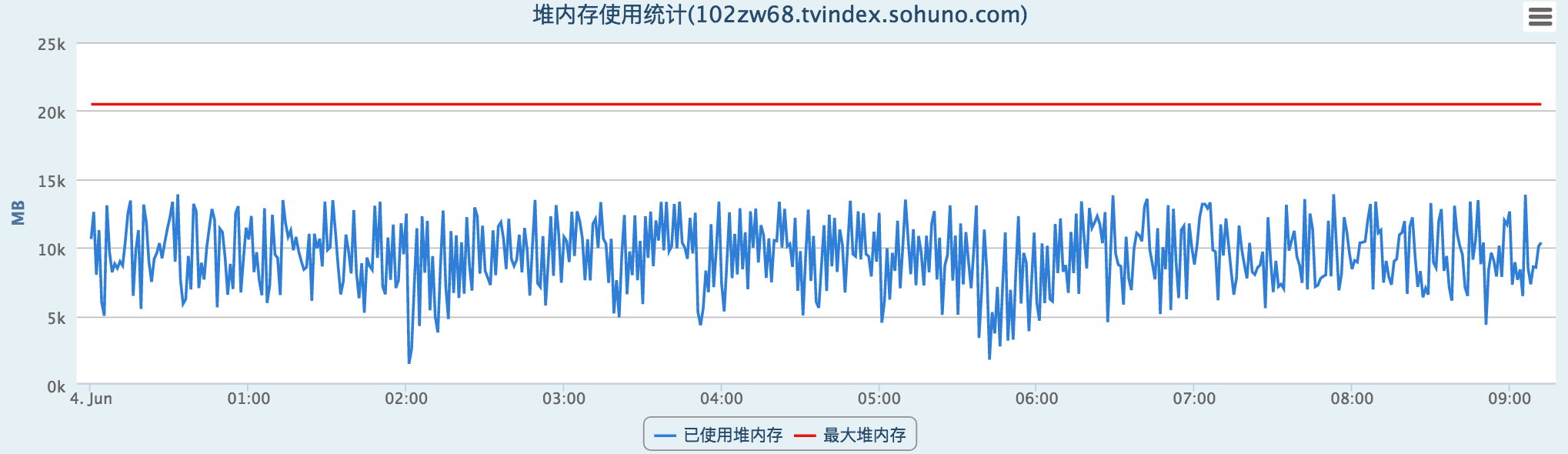
所以这里可以初步怀疑是堆外内存造成的fullgc。
三、分析原因: 堆外内存不足
由于本机器显示配置了MaxDirectMemorySize为7G,同时配置RegionServer的blockCache使用堆外内存作为二级缓存6G,也就是剩下给RegionServer的只有1G(堆外内存是预分配)。
根据JVM的原理,当堆外内存不足时,触发fullgc。
|
|
从日志看出,从第二次分配开始,就会触发fullgc,但是heap几乎就没怎么用,同时没有打印堆外内存信息
|
|
如果加-XX:+DisableExplicitGC,就不会触发System.gc(),直接会发生OOM。

这里可以参考毕玄的一篇文章:http://hellojava.info/?p=56
四、RegionServer与堆外内存
从日志看RegionServer在执行flush操作将数据刷到Hfile(HDFS,一般是多备份,通过网络),其中涉及到了数据传输和HFile远程读取,看下HBase源码应该是用到了NIO。
|
|
大致意思:
- 因为堆外内存很难管理,所以HBase没有直接使用,但JDK会在大的读写时候主动使用堆外内存,而且有很多是ThreadLocal级别。
- 建议不使用原生客户端,可以考虑使用netty版本的客户端。
五、解决方法与注意事项
1.解决方法:
当原理清楚后,解决方法很简单:
- 不用bucket:这个要看系统是否需要这个。
- 增加堆外内存配置:例如不显示配置就是和xmx一致。
无论怎样调整:保证有足够的堆外内存可以使用,但要保证机器内存的稳定
2. 注意事项:
- 监控RegionServer配置一致性。
- 深入了解RegionServer原理。
六、参考文献
- CMS GC会不会回收Direct ByteBuffer的内存
- jvm-堆外内存GC问题
- HBASE-4956
- HDFS HBase NIO相关知识
- standard hbase client, asynchbase client, netty and direct memory buffers
- Warn if hbase.bucketcache.size too close or equal to
附注一个bucketCache的统计,可以看到堆外内存是几乎没用,而且也可以确认堆外内存是预分配的。
|
|